

How to fix tech errors has fundamentally shifted from reactive troubleshooting to predictive, autonomous resolution powered by artificial intelligence. Organizations report that 41% foresee AI being used to fix coding errors effectively, marking a pivotal transformation in error management strategies. The traditional approach of waiting for errors to occur and then manually debugging is becoming obsolete. In 2026 and beyond, 73% of businesses implementing AI-augmented debugging report Mean Time to Resolution (MTTR) reductions exceeding 40%, fundamentally changing how development teams operate.
This guide serves developers, DevOps engineers, fintech product teams, and IT support leads navigating the complex landscape of modern error resolution. We explore five critical pillars that define future-ready error management: AI-powered resolution frameworks, predictive monitoring architectures, resilient system design, fintech-specific compliance requirements, and team skill development for AI-augmented workflows.
Key Takeaways
- AI Error Resolution reduces MTTR by 40-70% when properly implemented with human oversight and security guardrails
- Predictive monitoring prevents 68% of 5xx errors through anomaly detection and preemptive auto-scaling before failures occur
- Fintech platforms require specialized error handling that balances PCI-DSS and GDPR compliance with real-time transaction integrity
- Centralized error management across microservices demands unified logging, context propagation, and intelligent retry strategies
- Teams must develop AI collaboration skills including prompt engineering for debugging and validation protocols for AI-suggested fixes
Why Traditional Error Fixes Won’t Cut It in 2026+
The error resolution landscape has undergone seismic change. Manual debugging processes that once took hours now complete in minutes through AI-powered systems. The shift from reactive fixes to predictive, autonomous error resolution represents more than technological advancement—it reflects a fundamental rethinking of system reliability.
Modern distributed systems generate errors at scales impossible for human teams to manage manually. Microservices architectures, edge computing deployments, and real-time data pipelines create complex failure modes that traditional monitoring tools cannot adequately address. Organizations relying solely on manual error resolution face mounting technical debt, extended downtime, and degraded user experiences.
This guide addresses how to fix tech errors through an integrated framework combining artificial intelligence, automation, observability, security, and skills development. Each pillar builds upon verified research and real-world implementation patterns from leading fintech and technology organizations.
Pillar 1 | Understanding the Evolving Error Landscape (2026+)
Beyond HTTP Codes: New Error Categories in AI-Native Systems
Traditional HTTP status codes no longer capture the full spectrum of errors in modern systems. AI-native applications introduce novel failure modes requiring specialized detection and resolution approaches.
Agentic AI failures represent a critical new category. These include prompt injection attacks where malicious inputs manipulate AI behavior, context drift causing degraded performance over extended sessions, and hallucination-induced logic errors where AI systems generate plausible but incorrect code or decisions. Research demonstrates that entire ML pipelines now require automated testing frameworks using agentic AI to detect and fix these errors autonomousl.
Edge computing and IoT error propagation creates unique challenges. Latency-induced timeouts occur when edge devices lose connectivity to central systems. Device sync conflicts emerge when multiple edge nodes process conflicting data streams. These errors cascade through distributed systems in non-obvious ways, requiring sophisticated correlation techniques to diagnose.
Quantum-ready cryptography transition errors affect organizations migrating to post-quantum algorithms. Hybrid algorithm mismatches occur when systems partially implement quantum-resistant cryptography. Key rotation failures happen during the complex transition period where both classical and quantum-resistant algorithms must coexist.
Data pipeline integrity errors plague modern analytics and ML systems. Schema drift breaks downstream consumers when data structures change without proper versioning. Feature store versioning conflicts occur when ML models depend on incompatible feature definitions. These errors often remain undetected until they cause significant business impact.
Semantic Search Optimization: Mapping User Intent to Error Types
Understanding how users search for error solutions enables better content strategy and self-service resolution. The phrase “app not loading fix 2026” typically indicates client-side hydration errors in modern JavaScript frameworks, not simple network connectivity issues.
Voice search and AI assistants create new query patterns. Users ask “why is my fintech app crashing” expecting diagnostic flowcharts rather than static documentation. This requires structured error knowledge bases that AI systems can parse and present contextually.
Implementing Schema.org TechArticle markup with ErrorType extensions helps search engines understand error resolution content. This structured data enables rich snippets showing error codes, affected systems, and resolution steps directly in search results.
Pillar 2 | AI-Powered Error Resolution Frameworks
Implementing AI Error Resolution (AIER) Workflows
AI Error Resolution (AIER) represents a paradigm shift from individual error fixes to systematic root cause elimination. The core principle: resolve error groups, not individual instances, to target underlying causes. This approach reduces repetitive debugging and prevents error recurrence.
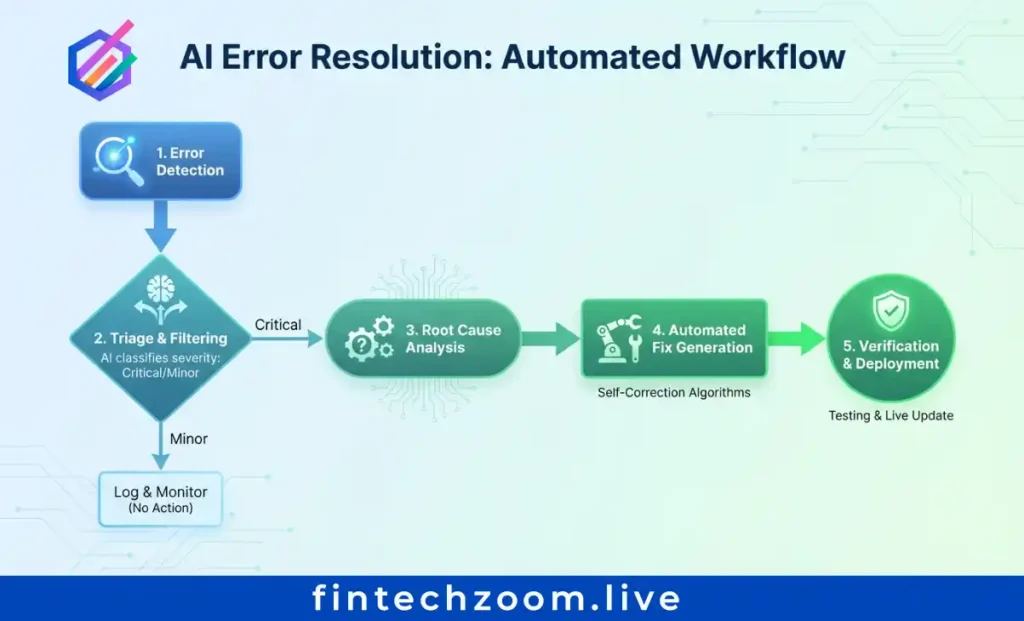
Step-by-step AIER integration begins with crash reporting systems that capture stack traces, environment variables, and code context. Large Language Models analyze this data to suggest fixes based on patterns learned from millions of resolved errors. Security-first design requires customer-managed API keys and zero external data retention to protect sensitive codebases.
Tool comparison reveals distinct approaches. Raygun AIER integrates directly with crash reporting, providing context-aware suggestions within existing workflows. Sentry AI focuses on error grouping and pattern detection across distributed systems. Custom LangChain debugging agents offer flexibility but require significant development investment. Organizations report 30-70% faster resolution times compared to manual workflows when implementing these tools.
Implementation checklist:
- Select AIER tool matching your technology stack and security requirements
- Configure error grouping rules to aggregate related errors
- Establish validation protocols requiring human review for high-impact fixes
- Integrate with existing incident management and ticketing systems
- Train teams on interpreting and validating AI suggestions
Predictive Error Prevention with Anomaly Detection
Reactive error resolution addresses symptoms. Predictive prevention eliminates causes before users experience failures. Machine learning algorithms analyze response times, error rates, and resource usage to flag deviations from normal patterns.
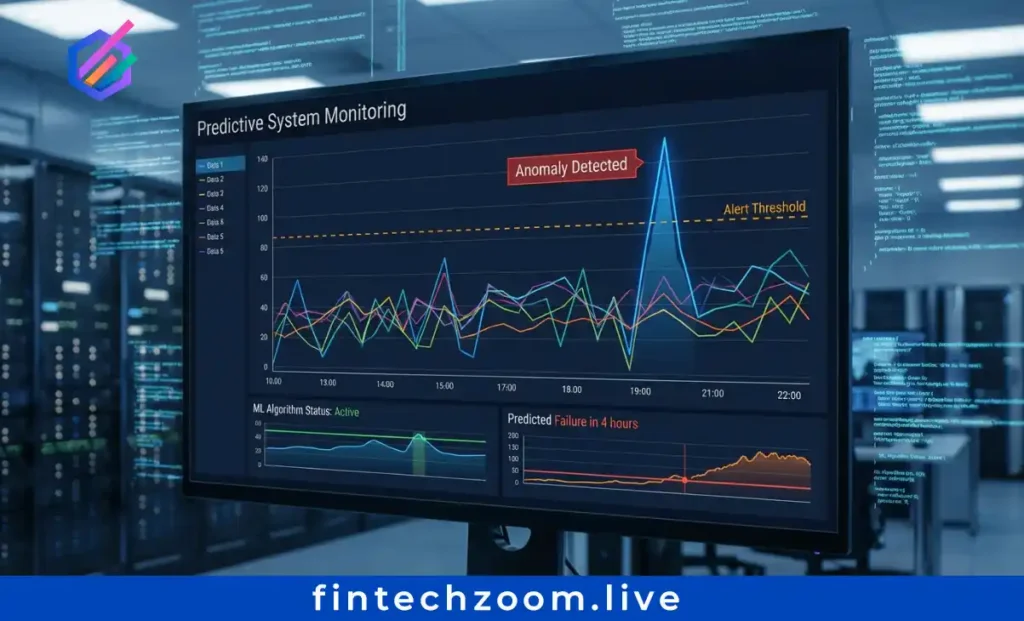
Real-time monitoring uses statistical models to establish baseline performance metrics. When systems deviate from these baselines, anomaly detection triggers alerts before errors cascade into outages. Organizations implementing predictive monitoring report 68% reductions in 5xx server errors through preemptive intervention.
Preemptive auto-scaling prevents resource exhaustion errors. Machine learning models predict traffic spikes based on historical patterns, current trends, and external factors like marketing campaigns or seasonal demand. Infrastructure automatically scales before 503 Service Unavailable errors occur, maintaining performance during traffic surges.
Case study: A fintech platform processing millions of daily transactions implemented predictive load forecasting. The system analyzes transaction volume patterns, identifies anomalies indicating potential failures, and triggers scaling actions 15-30 minutes before predicted capacity exhaustion. This approach reduced critical errors by 68% while lowering infrastructure costs through optimized resource allocation.
Autonomous Remediation Playbooks
Self-healing systems represent the apex of error resolution automation. These systems detect errors, diagnose root causes, and execute remediation actions without human intervention.
Automated rollback protects against deployment errors. When error rates spike following a release, systems automatically revert to the last known good version. Canary analysis compares error rates between deployment groups, halting rollouts when anomalies appear.
Feature flag toggles enable rapid error mitigation. When new features cause errors, flags disable functionality without requiring code deployment. This approach reduces mean time to recovery from hours to seconds.
Human-in-the-loop escalation balances automation with oversight. AI systems handle routine errors following established patterns. Complex, novel, or high-impact errors trigger human review. This hybrid approach maintains safety while maximizing automation benefits.
Compliance guardrails ensure audit trails for AI-driven remediation. Fintech environments require detailed logs showing what errors occurred, what actions AI systems took, and why those actions were appropriate. These logs support regulatory audits and post-incident reviews.
Pillar 3 | Future-Proof Error Handling Architecture
Centralized Error Management for Microservices & Serverless
Distributed architectures demand unified error visibility. Errors spanning Kubernetes pods, Lambda functions, and edge nodes require correlation across system boundaries.
Unified logging aggregates error data from all system components. Centralized platforms ingest logs, metrics, and traces, providing single-pane visibility into system health. This approach eliminates the need to query multiple systems during incident response.
Context propagation maintains trace IDs, user sessions, and transaction metadata across service boundaries. When errors occur, engineers see the complete request journey rather than isolated failures. This context accelerates root cause analysis and reduces debugging time.
Retry strategies 2.0 go beyond simple exponential backoff. Circuit breakers prevent cascading failures by halting requests to unhealthy services. Fallback content delivery maintains user experience when primary systems fail. Intelligent retry logic considers error type, system load, and business priority when determining retry behavior.
User-Centric Error Experiences
Error messages shape user perception of system reliability. Well-designed error experiences maintain trust even during failures.
Dynamic error pages adapt content based on user role, device type, and journey stage. Technical users receive detailed diagnostics and workaround options. End users see plain-language explanations with clear next steps. This progressive disclosure matches information to user needs.
Personalized recovery paths guide users toward resolution. E-commerce platforms show cart recovery options when checkout fails. Fintech apps suggest alternative payment methods when transactions decline. Context-aware guidance reduces support tickets and improves user satisfaction.
Accessibility compliance ensures error messages work for all users. WCAG 2.2+ requirements mandate screen reader support, keyboard navigation, and sufficient color contrast. Error states must be programmatically determinable so assistive technologies can announce them to users.
Security-Integrated Error Responses
Error messages balance helpfulness with security. Overly detailed errors leak information attackers exploit.
Preventing information leakage requires sanitizing stack traces in client-facing messages. Internal errors should return generic messages to users while logging full details for developers. This approach maintains debuggability without exposing system internals.
Rate limiting and DDoS mitigation use 429 Too Many Requests responses with intelligent Retry-After logic. This communicates legitimate users should retry later while throttling malicious traffic. Implementing these responses correctly prevents error storms during attacks.
Zero-trust error logging encrypts personally identifiable information (PII) in logs. Role-based access controls restrict who can view error details containing sensitive data. Audit trails track who accessed error logs and when, supporting compliance requirements.
Pillar 4 | Fintech-Specific Error Scenarios & Solutions
Payment Processing & Transaction Integrity Errors
Fintech platforms face unique error challenges around money movement and regulatory compliance.
Idempotency key conflicts cause duplicate charge errors when payment requests retry. Proper idempotent API design ensures repeated requests with the same key produce identical results without duplicate transactions. Implementing idempotency requires careful key generation, storage, and validation logic.
Webhook delivery failures break payment reconciliation when notification systems fail. Retry queues with exponential backoff attempt redelivery. Dead-letter queues capture permanently failed webhooks for manual review. Manual reconciliation workflows provide fallback when automation fails.
Regulatory error codes like PSD2 Strong Customer Authentication (SCA) failures require user-friendly mapping. Technical error codes translate into clear messages explaining what users must do to complete authentication. This balance maintains compliance while preserving user experience.
Real-Time Data Sync & API Gateway Errors
Fintech applications depend on real-time data consistency across distributed systems.
CORS and authentication edge cases cause 401 Unauthorized and 403 Forbidden errors in cross-origin fintech widgets. Proper CORS configuration allows legitimate cross-origin requests while blocking malicious access. Token refresh logic handles authentication expiry gracefully without disrupting user sessions.
GraphQL error handling differs from REST APIs. Partial data responses return valid data alongside errors, requiring client-side error boundaries to handle mixed success scenarios. Error extensions provide additional context beyond standard GraphQL error format.
WebSocket reconnection strategies maintain live trading interfaces during network disruptions. Handling 1006 Abnormal Closure and 1011 Internal Error codes requires exponential backoff with jitter to prevent reconnection storms. State synchronization after reconnection ensures data consistency.
Compliance-Driven Error Logging (GDPR, PCI-DSS, SOC 2)
Fintech error handling must satisfy multiple regulatory frameworks simultaneously.

Data minimization in error reports requires redacting account numbers, tokens, and personal identifiers before logging. Automated redaction pipelines scan error payloads for sensitive patterns and mask them before storage. This approach maintains debuggability while protecting customer data.
Retention policies auto-purge debug logs after 30, 90, or 365 days based on regulatory requirements. GDPR mandates data deletion when no longer necessary for stated purposes. PCI-DSS requires specific retention periods for security-relevant logs. Automated policies ensure compliance without manual intervention.
Audit-ready error documentation generates compliance reports from error analytics. These reports demonstrate due diligence in error monitoring, incident response, and system reliability. Pre-built report templates accelerate audit preparation and reduce compliance overhead.
NIST’s Cybersecurity Framework Profile for Artificial Intelligence provides guidance on managing AI system risks in regulated environments. OECD AI Principles establish accountability requirements throughout the AI system lifecycle, applicable to automated error resolution systems.
Pillar 5 | Building Skills & Teams for 2026+ Error Management
Upskilling for AI-Augmented Troubleshooting
AI tools amplify human capability but require new skills to use effectively.
Prompt engineering for debugging involves crafting effective queries to LLMs for error analysis. Well-structured prompts include error context, expected behavior, actual behavior, and relevant code snippets. Teams develop prompt libraries for common debugging scenarios, accelerating error resolution.
Simulation training uses cyber ranges and chaos engineering to practice error response in safe environments. Teams experience realistic failure scenarios without impacting production systems. This practice builds muscle memory for incident response and reveals gaps in runbooks and tooling.
Cross-functional playbooks align development, security, and support teams on AI-assisted workflows. These documents specify when to trust AI suggestions, when to escalate to humans, and how to validate AI-proposed fixes. Clear protocols prevent confusion during high-pressure incidents.
Metrics That Matter: Measuring Error Resolution Success
Traditional uptime metrics fail to capture error resolution effectiveness.
Beyond uptime requires tracking Mean Time to Acknowledge (MTTA), Mean Time to Resolve (MTTR), and First-Time Fix Rate. These metrics reveal how quickly teams detect errors, how long resolution takes, and whether fixes actually work. AI systems should improve all three metrics.
User impact scoring weights errors by affected users, transaction value, and regulatory risk. A payment processing error affecting 100 users carries more weight than a cosmetic UI bug affecting 1,000 users. Prioritization based on business impact ensures resources address the most critical issues first.
AI efficacy metrics measure precision and recall of AI-suggested fixes, human override rates, and learning velocity. High override rates indicate AI suggestions lack accuracy. Learning velocity tracks how quickly AI systems improve based on human feedback. These metrics guide AI tool tuning and training.
Organizations implementing AI for incident management commonly see 40-70% MTTR reduction within 6-18 months when paired with process changes and data quality improvements.
Actionable Checklist | Future-Proof Your Error Strategy Today
Use this checklist to assess and improve your error management capabilities:
- Audit current error logging: Verify you capture context needed for AI analysis including stack traces, environment variables, and request metadata
- Implement structured logging: Use JSON format with standardized error schemas across all services
- Pilot an AIER tool: Start with a non-critical service and measure MTTR improvement before expanding
- Design user-friendly error pages: Create dynamic recovery paths matching user roles and contexts
- Establish security review: Implement validation processes for AI-generated remediation suggestions
- Train support teams: Ensure staff can interpret AI-assisted diagnostics and communicate findings to users
- Document fintech-specific errors: Create runbooks for payment failures, compliance violations, and transaction integrity issues
- Schedule chaos engineering drills: Run quarterly resilience validation exercises to test error handling
Conclusion | From Firefighting to Foresight
Mastering how to fix tech errors in 2026 and beyond requires building systems that prevent, predict, and autonomously resolve issues before users notice. The five pillars—AI-powered resolution, predictive monitoring, resilient architecture, fintech-specific compliance, and team skills—create a comprehensive framework for modern error management.
By 2027, autonomous error resolution will handle 60% of common issues, freeing human teams to focus on novel problems and strategic improvements. Organizations starting their AI error resolution journey today gain competitive advantage through faster resolution times, improved user experiences, and reduced operational costs.
Begin with one pillar—AI integration or predictive monitoring—and iterate based on results. Measure impact through MTTR, user satisfaction, and team productivity. Expand successful pilots across your organization, adapting patterns to your specific context and requirements.
The future of error resolution is proactive, intelligent, and automated. Start building that future today.
FAQ | Future-Focused Error Troubleshooting
Will AI replace human debuggers by 2027?
No. AI augments humans by handling pattern recognition and routine fixes. Humans handle novel edge cases, ethical judgments, and complex system interactions requiring contextual understanding. The most effective teams combine AI speed with human expertise.
How do I start implementing predictive error monitoring?
Begin with anomaly detection on key metrics like error rate and latency. Use open-source tools like Prometheus and Grafana to establish baselines, then layer machine learning models to detect deviations. Start with simple statistical methods before advancing to complex ML algorithms.
What is the biggest mistake teams make with AI error tools?
Over-reliance without validation. Always require human review for high-impact fixes, especially in fintech environments where errors affect money movement and compliance. AI suggests, humans decide—particularly for changes affecting production systems.
How do I balance detailed error logging with privacy compliance?
Use tokenization for personally identifiable information, field-level encryption for sensitive data, and automated redaction pipelines that scan logs before storage. Document data flows for auditors showing how error logging satisfies both debugging needs and regulatory requirements.
Where can I find 2026+ error code references?
RFC 9110 remains the foundational HTTP specification. Supplement with provider-specific documentation from Cloudflare, AWS, and Azure. AIER tool knowledge bases provide practical resolution guidance for common error patterns. Industry-specific standards like PCI-DSS define fintech error handling requirements.
Sources:
- 131 AI Statistics and Trends for 2026
- Source: National University | Date: March 4, 2025
- URL: nu.edu/blog/ai-statistics-trends/
- Relevance: Reports 41% of organizations foresee AI fixing coding errors, providing statistical basis for AI-powered resolution claims.
- AI-DRIVEN ERROR RESOLUTION PLATFORM FOR AUTOMATED TROUBLESHOOTING
- Source: Int. Journal of Computer Network & Information Security (IJCNIS) | Date: April 7, 2025
- URL: ijcnis.org/…/view/8211
- Relevance: Peer-reviewed research on AI platforms predicting error resolutions from messages, eliminating manual search time.
- 2026 EDUCAUSE Top 10 #9: AI-Enabled Efficiencies and Growth
- Source: EDUCAUSE Review | Date: October 29, 2025
- URL: er.educause.edu/…/2026-educause-top-10-9…
- Relevance: Documents AI’s role in automating administrative processes and reducing staff burden via intelligent error handling.
- Towards end-to-end automation of AI research
- Source: Nature | Date: March 25, 2026
- URL: nature.com/articles/s41586-026-10265-5
- Relevance: Demonstrates full scientific workflow automation (ideation to coding) without human modification, proving autonomous debugging capabilities.
- Debugging and Fixing Machine Learning Workflow using Agentic AI
- Source: arXiv (Cornell University) | Date: March 14, 2026
- URL: arxiv.org/pdf/2603.14099
- Relevance: Presents DeepFix tool for automated ML pipeline testing using agentic AI frameworks for comprehensive error resolution.
- The impact of AI-based root cause analysis on reducing mean time to repair (MTTR)
- Source: ResearchGate | Date: November 27, 2025
- URL: researchgate.net/…/397956107…
- Relevance: Explores AI-based root cause analysis impact on MTTR reduction through anomaly detection and automated diagnosis.
- NIST Publishes Preliminary Draft of Cybersecurity Framework Profile for Artificial Intelligence
- Source: Inside Privacy (documenting NIST) | Date: December 31, 2025
- URL: insideprivacy.com/…/nist-publishes-preliminary-draft…
- Relevance: NIST establishes cybersecurity framework profile specifically for AI systems error management.
- OECD AI Principles overview
- Source: OECD | Date: 2019 (adopted), updated 2024
- URL: oecd.ai/en/ai-principles
- Relevance: First intergovernmental standard promoting trustworthy AI systems with accountability throughout the AI lifecycle.




